大麦h5页面反爬机制破解
破解日期: 20250911
大麦爬虫的加密逻辑经常会变化,如果发现破解方式过期了可以联系我
先上代码
import json
import time
from hashlib import md5
import requests
import zstandard as zstd
token = "7e82ad328eff6fccbd6e1a12b11fb273"
timestamp = int(time.time() * 1000)
app_key = "12574478"
data = {
"returnTouristTicketItem": True,
"targetType": 0,
"dataSource": 2,
"pageIndex": 2,
"pageSize": 20,
"isQueryReply": True,
"isQueryIpInfo": True,
"contentLabelList": "[0]",
"isQueryCommentEntry": True,
"sort": 2,
"onTop": False,
"itemId": "969591124546",
"isQueryContent": True,
"isQueryGradeStat": True,
"isShowContentLabel": True,
"commentTypes": "[32,62,65,66]",
"dataModule": 1,
"platform": "8",
"comboChannel": "2",
"dmChannel": "damai@damaih5_h5",
}
data_str = json.dumps(data, separators=(",", ":"), ensure_ascii=False)
sign_str = f"{token}&{timestamp}&{app_key}&{data_str}"
sign = md5(sign_str.encode("utf-8")).hexdigest()
url = "https://mtop.damai.cn/h5/mtop.damai.wireless.comment.list.get/3.3/"
params = {
"jsv": "2.7.5",
"appKey": app_key,
"t": timestamp,
"sign": sign,
"api": "mtop.damai.wireless.comment.list.get",
"v": "3.3",
"H5Request": "true",
"type": "originaljson",
"timeout": "10000",
"dataType": "json",
"valueType": "original",
"forceAntiCreep": "true",
"antiCreep": "true",
"useH5": "true",
"data": data_str,
}
headers = {
"accept": "application/json",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8",
"content-type": "application/x-www-form-urlencoded",
"cookie": "_m_h5_tk=7e82ad328eff6fccbd6e1a12b11fb273_1757590449747; _m_h5_tk_enc=bf1f5037f1cc13df880ab00dd336f488;",
"origin": "https://m.damai.cn",
"referer": "https://m.damai.cn/shows/pages/all-comments.html?from=def&labelType=0&projectId=969591124546&spm=a2o71.product_detail.evaluate.tag_0&sqm=dianying.h5.unknown.value&tagType=1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36",
}
response = requests.get(url, params=params, headers=headers)
encoding = response.headers.get("Content-Encoding", "")
raw = response.content
try:
if encoding == "zstd":
dctx = zstd.ZstdDecompressor()
text = dctx.decompress(raw).decode("utf-8", errors="replace")
else:
text = raw.decode("utf-8", errors="replace")
except Exception as e:
print("解码失败:", e)
text = response.text
print(text)解析
appKey是固定不变的,从js代码中得到计算sign值的时候appKey一直没有发生变化

n.subDomain根据url可以得知,这是固定值m, 由此可知s === '12574478'
token可以观察到和cookie中一致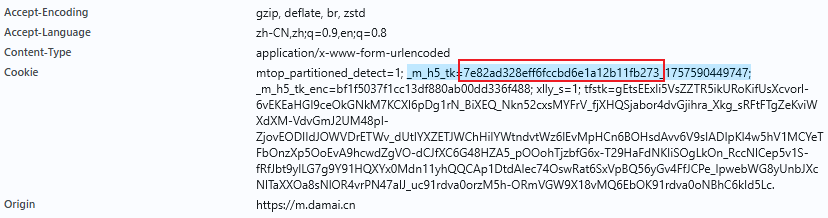
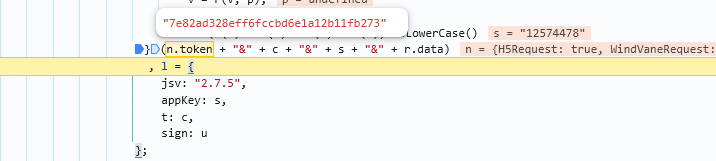
sign值的计算可以通过上述的图片得出data_str = json.dumps(data, separators=(",", ":"), ensure_ascii=False) sign_str = f"{token}&{timestamp}&{app_key}&{data_str}" sign = md5(sign_str.encode("utf-8")).hexdigest()之所以使用
json.dump的原因是,js中处理这个data_str的值的方式是token + "&" + timestamp + "&" + appKey + "&" + JSON.stringify(data),而这在python中应该进行必要处理。由于大麦对返回值做了编码处理
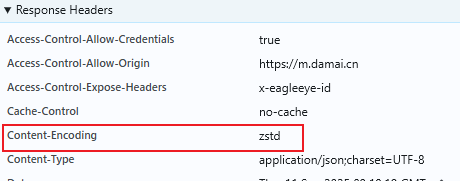
所以我们需要对输出的text做decode操作,这里需要安装zstandard。
内容仅供学习,请勿进行任何违法行为